Setting up the project
Create a project
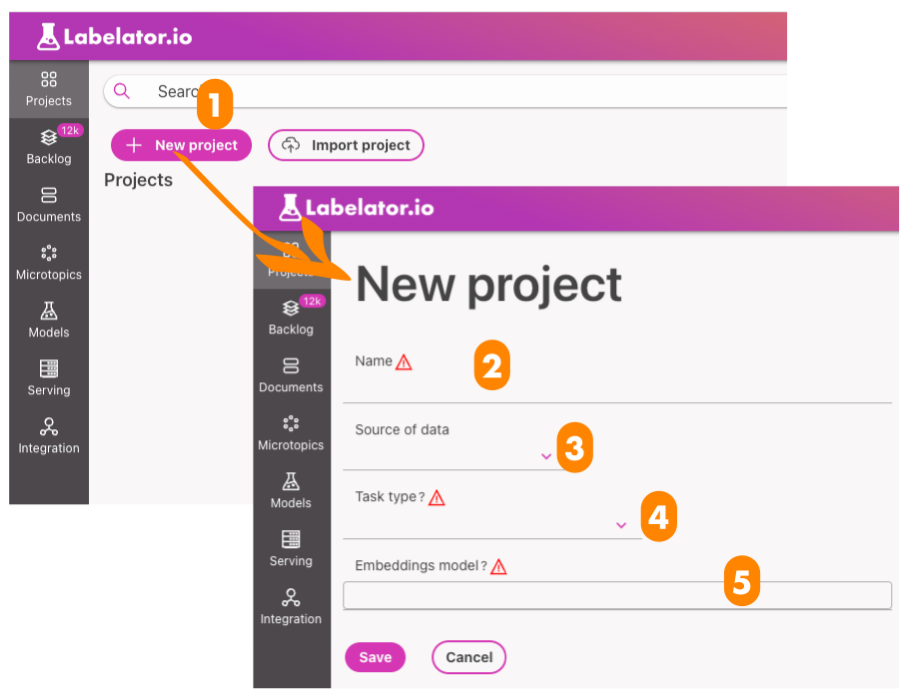
- Navigate to the "Projects" section and select "New project."
- Fill out the form by providing at least a unique name and task type for the project.
- Optionally,
Alternatively, you can initialize data later through the API without setting up a source of data. (please refer to Labalator.io API or Python SDK documentation)
The task type is a required field and defines the machine learning task that the project will be optimized for.
- TextClassification: a task for training a model to assign a single label to a text based on its content
- MultiLabelTextClassification: a task for training a model to assign multiple labels to a single document based on its content
- TextSimilarity: a task for fine-tuning a model to determine the similarity of two documents or records
- QuestionAnswering (currently in beta): a task for training a model to provide the best possible answer to a question
- The embeddings model is another required field and determines the source models used to encode the meaning of documents. It is important to consider the language and domain of the documents when selecting a model. Predefined options are available, but any SentenceTransformer-compatible model from the Hugging Face Hub can also be used.
Full list of available models can be found here: https://huggingface.co/models?pipeline_tag=sentence-similarity
Machine learning models can vary in quality, size (which can impact the speed of inference), supported languages, and the length of text they can consider during inference (with any excess text being discarded). It is important to take these factors into consideration when selecting a model, as they can impact the performance and accuracy of the model.
In addition to these general considerations, it is also important to consider the specific domain of your problem. If you are working with a very specific domain, it may be beneficial to fine-tune an existing model to better suit your needs by training a Text Similarity model first. This model can be trained alongside a classification project as well. By fine-tuning a model to your specific domain, you may be able to improve the labeling suggestions when using Labelator.io
Setting up the labels
For classification projects, you can define the labels that you wish the model to be trained for.
Label names cannot contain white space.
You can also assign unique settings to each label, such as:
- An Icon and Color for label
- Keybindings to help you assign a key for controlling the labeling process via keyboard and label faster
- Keywords, which will be highlighted during labeling to help you notice these words in longer sentences.
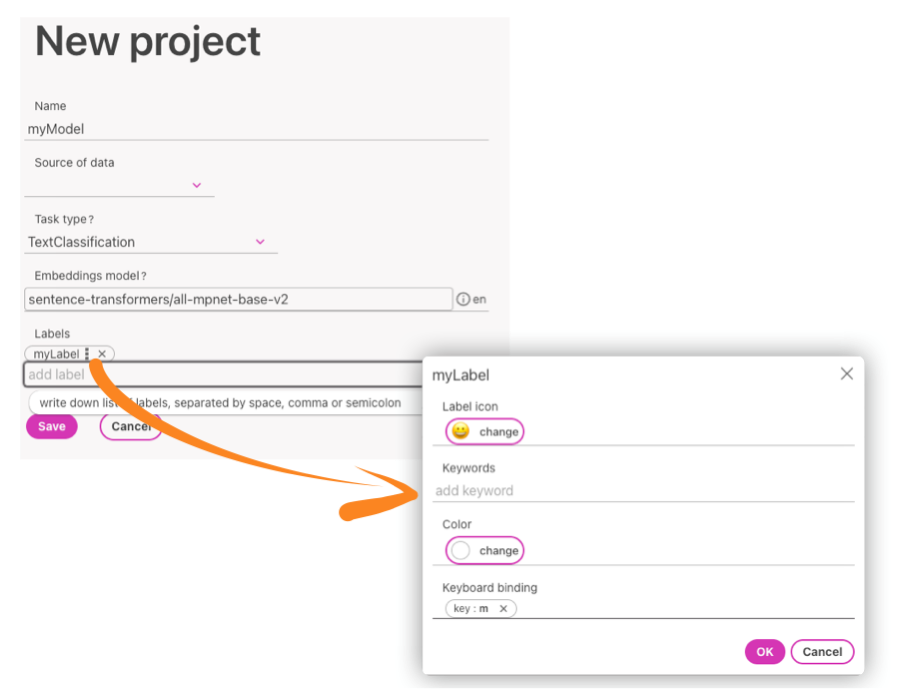
New labels as well as keywords can be assinged later during labeling
Import data from file
you can initialize data for the project by providing files in the formats of .xlsx, .csv, or .json.
Each file must have a text column.
Optionally, you can provide a key column that would be used as an user-defined identifier.
Any other columns of string data type will be imported as metadata (columns with other data-type will be discarded).
Import data from BigQuery
You can load data also from Google BiqQuery. A query text must be provided and you also need to authenticate to your google account that has granted access to the data table you with to query from.
Similarly to importing data from file, the query must return a text column. Other columns like key, or other metadata columns are optional.
Import data with pandas
Our Python SDK has a add_documents method that allows you to upload any pandas DataFrame.
Please refer to the tutorial notebook so see how to import data with pandas.